2012.
Les statistiques du web mobile commencent à exploser.
Les entreprises de la tech flairent le filon des applications web responsives design accessibles via les navigateurs web.
Parmi elles, Facebook.
Sa première web app pour iOS est créée la même année. Sauf que les experts de l’expérience utilisateur du réseau social remarquent vite un gros problème : l’interface-utilisateur n’est pas fluide.
Les ingénieurs de la firme se creusent les méninges… et décident de créer une application mobile native pour iOS.
Et là encore, nouveau problème, leurs APIs REST renvoient trop d’informations et ne sont pas adaptées aux spécifications du développement mobile.
Les APIs REST consomment beaucoup trop de bande passante. Ralentissent la version mobile du réseau social. Et surtout, surchargent les serveurs en back-office pour rien.
De là, vient l’idée à Lee Byron et à deux de ses collègues de créer un nouveau langage de requêtes : GraphQL.
Publié pour la première fois en 2012, il devient open-source en 2015, et depuis, il ne cesse de séduire les développeurs web et mobiles.
Et aujourd’hui, on va parler de GraphQL, quels avantages vous pouvez en tirer et comment il fonctionne.
Let’s go.
Qu’est-ce que GraphQL ?
Pour comprendre GraphQL, vous devez savoir ce qu’est une API (si si, c’est important). Une API, ou “Application Programming interface”, est un ensemble de protocoles qui permettent à deux composants logiciels de communiquer.
Elles sont énormément utilisées dans les architectures client-serveur pour permettre à l’utilisateur de récupérer des données depuis une base de données.
C’est au concepteur-développeur de l’application de choisir et de concevoir l’interface de programmation qui sera utilisée.
GraphQL, ou Graph Query Language, est un langage de requêtes et un environnement d’exécution côté serveur pour API.
Sa particularité ? C’est la requête du client qui définit la structure des données qu’il veut.
Particularité qui a déjà séduit plusieurs entreprises, dont :
- PayPal ;
- Coursera ;
- Dailymotion ;
- GitHub ;
- Meta.
Vous en trouverez plus en vous rendant sur le site de la fondation GraphQL (voici une partie de la liste).

Et cette nuance est importante. Car les autres APIs les plus utilisées sont les APIs REST (Representational State Transfer).
Et elles vous renvoient des informations prédéfinies par le développeur qui a conçu l’architecture serveur. Même si elles ne correspondent pas aux besoins de l’utilisateur.
Parfois, elles envoient trop de données, et côté client, on ne sélectionne que celles qui nous intéressent. On parle d’over-fetching.
Parfois, à l’inverse, elles n’envoient pas toutes les informations, ce qui oblige à faire plusieurs appels sur la base de données. On parle d’under-fetching.
Ces deux problèmes peuvent être évités grâce à une API GraphQL.
Comment fonctionne une API GraphQL ?

Au sein d’une API GraphQL, toutes les requêtes sont des requêtes POST avec, en attribut, une structure de données.
Et c’est la structure de données passée en paramètre qui contient les noms des attributs que l’on souhaite recevoir en retour.
À l’intérieur du code de l’API, vous trouverez deux catégories de données :
- les données « Types » ;
- les données « Champs ».
Et parmi les objets, vous trouverez 3 types d’objets différents :
- les objets « Requêtes », qui contiennent toutes les requêtes acceptées par l’API et qui vérifient que les formats reçus sont autorisées ;
- les objets « mutation » qui définissent toutes les actions possibles et qui permettent de faire des modifications sur les modèles définis ;
- les objets « abonnement », qui définissent les modèles de la base de données.
Bon, ok, tout ça, c’est un peu théorique.
Alors voici un exemple de code-source.
On va définir, en GraphQL, une structure de données représentant un concessionnaire automobile (juste son nom et son emplacement). Ensuite, on va récupérer son emplacement.
Voici ce que ça donne.
type Concessionnaire {
nom: String
emplacement: String
voitures: String
}
Définition du graphe de données.
Vous voyez à quel point c’est simple ? Let’s go pour un appel en javascript.
const { ApolloClient, InMemoryCache, gql } = require('@apollo/client');
// Remplacez l'URL par l'endpoint de votre serveur GraphQL
const graphqlEndpoint = 'https://votre-serveur-graphql.com/graphql';
// Initialisez le client Apollo
const client = new ApolloClient({
uri: graphqlEndpoint,
cache: new InMemoryCache(),
});
// Définissez votre requête GraphQL
const GET_EMPLACEMENTS = gql`
query {
concessionnaires {
emplacement
}
}
`;
// Effectuez la requête
client.query({ query: GET_EMPLACEMENTS })
.then(result => {
const emplacements = result.data.concessionnaires.map(concessionnaire => concessionnaire.emplacement);
console.log('Emplacements des concessionnaires (GraphQL) :', emplacements);
})
.catch(error => {
console.error('Erreur lors de la récupération des données (GraphQL) :', error);
});
Prêtez bien attention à la définition du schéma de requête.
const GET_EMPLACEMENTS = gql`
query {
concessionnaires {
emplacement
}
}
`;
Clairement, on fait comprendre au serveur qu’on ne veut que l’emplacement et rien d’autre.
Ainsi, pas besoin de filtrer le résultat qu’il retourne.
Si on fait la même chose avec une API REST, voici ce que ça donne :
const axios = require('axios');
// Remplacez l'URL par l'endpoint de votre API REST
const restEndpoint = 'https://votre-api-rest.com/concessionnaires';
// Effectuez une requête GET pour récupérer les données
axios.get(restEndpoint)
.then(response => {
const concessionnaires = response.data;
const emplacements = concessionnaires.map(concessionnaire => concessionnaire.emplacement);
console.log('Emplacements des concessionnaires (REST) :', emplacements);
})
.catch(error => {
console.error('Erreur lors de la récupération des données (REST) :', error);
});
Vous voyez la nuance sur les lignes :
const concessionnaires = response.data;
const emplacements = concessionnaires.map(concessionnaire => concessionnaire.emplacement);
Ici, on récupère toutes les informations des concessionnaires. Et après ça, on extrait le champ qui nous intéresse.
Imaginez un peu si on avait plus d’informations sur les concessionnaires :
- Des images de plusieurs centaines de voitures au format .png ;
- Des vidéos de présentations ;
- Des dizaines d’informations textuelles supplémentaires, etc.
Devinez quoi ? On aurait dû tout transférer depuis les serveurs avec une API REST pour, au final, ne garder qu’une seule colonne.
Bon, c’est un peu exagéré, généralement, on définit une API spécifique qui ne renvoie que des données précises pour chaque cas. Mais vous voyez l’idée.
Pourquoi GraphQL est (parfois) un meilleur choix qu’une API REST ?
Quel API choisir pour concevoir vos logiciels ? À quels protocoles allez-vous faire confiance pour le transfert de vos données ?
Le cabinet Postman a posé la question à plusieurs développeurs dans le monde. Et voici les résultats qu’ils ont obtenus :
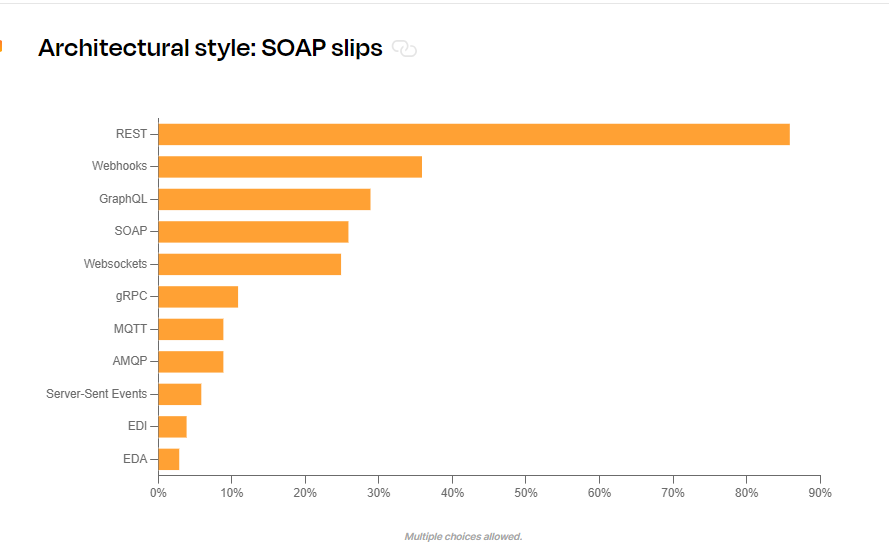
source : 2023 State of API Report, Postman
Dans les faits, 89 % des devs utilisent des APIs Rest dans leur pile technique contre à peine 29 % pour les APIs GraphQL (ils pouvaient choisir plusieurs réponses).
Qu’est-ce qui explique ces choix ?
1ʳᵉ Réponse : vos besoins applicatifs (ceux que vous avez listés dans votre cahier des charges).
Et pour être sûr de tirer un maximum d’avantages de GraphQL, incluez-la comme critère lorsque vous composez votre équipe de développeurs.
2ᵉ réponse : les avantages et les inconvénients de GraphQL.
Et justement, voyons-les tout de suite.
3+1 Avantages de GraphQL
GraphQL a 4 avantages majeurs comparé à REST.
1 – Vous évitez l’under-fetching
L’under-fetching se produit lorsqu’une requête ne retourne pas toutes les données dont le programmeur a besoin.
En conséquence, il doit encore faire un appel serveur et initier un autre transfert de données pour avoir toutes les informations qu’il veut.
Vous sentez la dégradation des performances de votre app venir ?
Du moins, ça se passe comme ça dans une API Rest.
Dans une API GraphQL, vous n’avez pas ce problème. Vous demandez des données, et le serveur vous les retourne, un point c’est tout.
2 – Vous évitez l’over-fetching
L’over-fetching est l’autre face de l’under-fetching.
Il se produit lorsque vous avez besoin d’une information, mais que l’API vous retourne tout un tas d’autres données dont vous n’avez pas besoin.
Sur les APIs REST, c’est fréquent.
On fait un appel à la base de données via une API dont les champs retours sont déjà spécifiés. Ensuite, après avoir consommé la bande passante du serveur et du client, on jette tous les champs qui ne nous intéressent pas.
Du gaspillage pur.
Et ça empire si vous avez besoin de données sur le même serveur, mais accessibles via des API différentes.
Heureusement, avec GraphQL, ça ne se produit pas.
Le développeur précise clairement les champs qu’il attend et le back-end lui fournit uniquement ceux-là.
Vous vous souvenez de l’extrait de code qu’on vous a fourni plus haut avec le concessionnaire ? C’est exactement ce qui s’y passe.
const concessionnaires = response.data;
const emplacements = concessionnaires.map(concessionnaire => concessionnaire.emplacement);
Avec l’API Rest, malgré le fait que l’on ne souhaite avoir que l’emplacement, on télécharge d’abord toutes les données renvoyées par le serveur.
L’over-fetching est particulièrement énervant pour les applications mobiles et web car elle les ralentit fortement.
3 – Gérer les versions n’a jamais été aussi simple
Vos applications évoluent. Les versions se succèdent et parfois ne se ressemblent pas.
Très souvent, vous ajouterez ou retirerez des fonctionnalités de l’app.
Problème : vos équipes de dev vont devoir modifier les champs retournés par l’API.
Si vous utilisez REST, apprêtez-vous à de longues journées à chercher exactement quelles fonctions dépendent de quelles APIs.
Essayez de retirer un champ dans une API alors qu’il est critique pour une fonction utilisant cette API… et une pluie de bugs informatiques et de crash vont vous tomber dessus.
À l’inverse, rajoutez trop de champs dans vos APIs pour faire tourner vos nouvelles fonctions, et vos systèmes informatiques vont ralentir. Sans compter les risques de vulnérabilité accrus aux cyberattaques.
(Si vous vous reconnaissez dans l’un de ces cas, notre chef de projet informatique peut vous aider à éviter que vos applications explosent. Faites-lui un message).
Bref, la gestion des versions d’un logiciel va vous obliger à aller toucher à vos APIs et aux requêtes serveurs qui les utilisent.
Sauf si vous utilisez GraphQL.
Alors non, les APIs GraphQL ne sont pas immuables. Mais elles ont une meilleure rétrocompatibilité, sont plus simples à faire évoluer et à adapter à vos nouveaux besoins.
4 – GraphQL vous facilitent l’accès aux données éparpillées dans plusieurs bases de données relationnelles
Voici ce à quoi ressemble l’architecture des bases de données typiques des grands groupes :
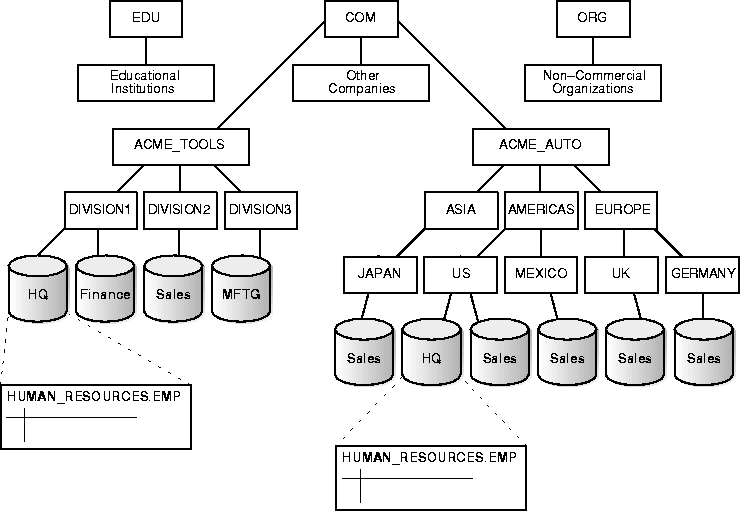
Source : Oracle https://docs.oracle.com/cd/A58617_01/server.804/a58227/ch21.html
Les silos représentent ici des bases de données.
Vous voyez où je veux en venir ? Les informations peuvent être contenues dans différents serveurs situés à des emplacements géographiques différents.
Et c’est logique : si votre entreprise ouvre une branche à Paris, vous voudrez très probablement stocker les informations de vos clients de Paris à proximité de Paris. Question de simplifier l’accès aux données de vos collaborateurs qui gèrent ces clients.
Par contre, vous n’avez pas besoin de dupliquer les informations de votre département Ressources Humaines sur place. Vous les garderez donc près de votre siège.
Et si, comme tous les GAFAM, vous décidez d’installer votre siège européen à Dublin, devinez quoi ? Vous allez assurément y stocker les informations sur vos ventes, vos finances, etc.
Pourquoi je vous parle de ça ?
Pour vous faire comprendre que vos données peuvent facilement être éparpillées dans des data centers aux 4 coins du monde.
Et il n’est pas rare que vous ayez besoin, dans une seule requête, d’informations situées dans plusieurs data centers différents.
Vos équipes de développement vont devoir faire appel à plusieurs APIs. Ensuite faire des JOIN/Merge en SQL entre les clés primaires et secondaires de leurs retours.
C’est fastidieux. Ça consomme énormément de ressources (électricité + bande passante). Enfin, ce flux de SELECT, JOIN et de MERGE diminuent la durée de vie de votre infrastructure informatique.
Pour au final ne récupérer que peu d’informations.
Avec une couche GraphQL, les performances de telles requêtes vont considérablement s’améliorer, car il s’appuie sur des technos web.
C’est ce qu’a fait Netflix lors de la création de son système de gestion des publicités Monet. En effet, ses pages devaient charger des informations éparpillées sur ses différents serveurs.
Grâce à l’ajout d’une couche de GraphQL, les pages qui chargeaient 10 MB de données n’avaient plus besoin que de 200 KB. Et les performances globales du système ont fait un boost de x8.

Les 4 inconvénients majeurs de GraphQL
Après tout ce qu’on a dit plus haut, on peut être tenté de se dire que GraphQL est la solution technique à tous vos problèmes.
Attendez.
Parce que les API GraphQL ont aussi leurs défauts.
1 – Pas de mise en cache côté serveur (ou trop complexe)
Avec une API Rest, vous savez exactement quelles informations le client va vous demander.
Et si le même client demande les mêmes informations plusieurs fois, vous pouvez les mettre en cache côté serveur pour gagner en vitesse.
C’est impossible ou très peu envisageable avec une API GraphQL.
La raison : la structure des données retours n’est pas définie côté serveur.
Une tactique utilisée par les développeurs GraphQL est de mettre les informations dans le cache du client. C’est moins efficace, mais ça marche.
2 – La courbe d’apprentissage du langage de requête peut être abrupte
REST est une norme d’échanges d’informations créée en 2000.
Ça fait 24 ans qu’elle est enseignée par défaut aux geeks et autres passionnés d’informatique par défaut.
Tous ceux qui s’intéressent aux codes informatiques et à la gestion des données doivent maîtriser par cœur la formule CRUD des API REST. (CRUD = CREATE READ UPDATE DELETE).
En conséquence, la transition du modèle CRUD vers les schémas, résolveurs, souscriptions et graphes de GraphQL peut s’avérer difficile.
3 – Il y a peu de développeurs spécialisés sur cette technologie (comparée aux API REST)
Si vous ne voulez pas, ou n’avez pas le temps de faire une montée en compétence, l’autre solution est d’embaucher un expert maîtrisant cette technologie.
Sauf que, vous vous en doutez, ils sont moins nombreux que ceux maîtrisant les interfaces de programmation d’applications REST.
En écrivant ces lignes, je suis allé faire un tour sur Fiverr, l’une des marketplace de freelance les plus populaires au monde.
J’ai fait une recherche sur le terme « Développeur API GraphQL » et ensuite, j’ai filtré les prestataires parlant français et/ou anglais.
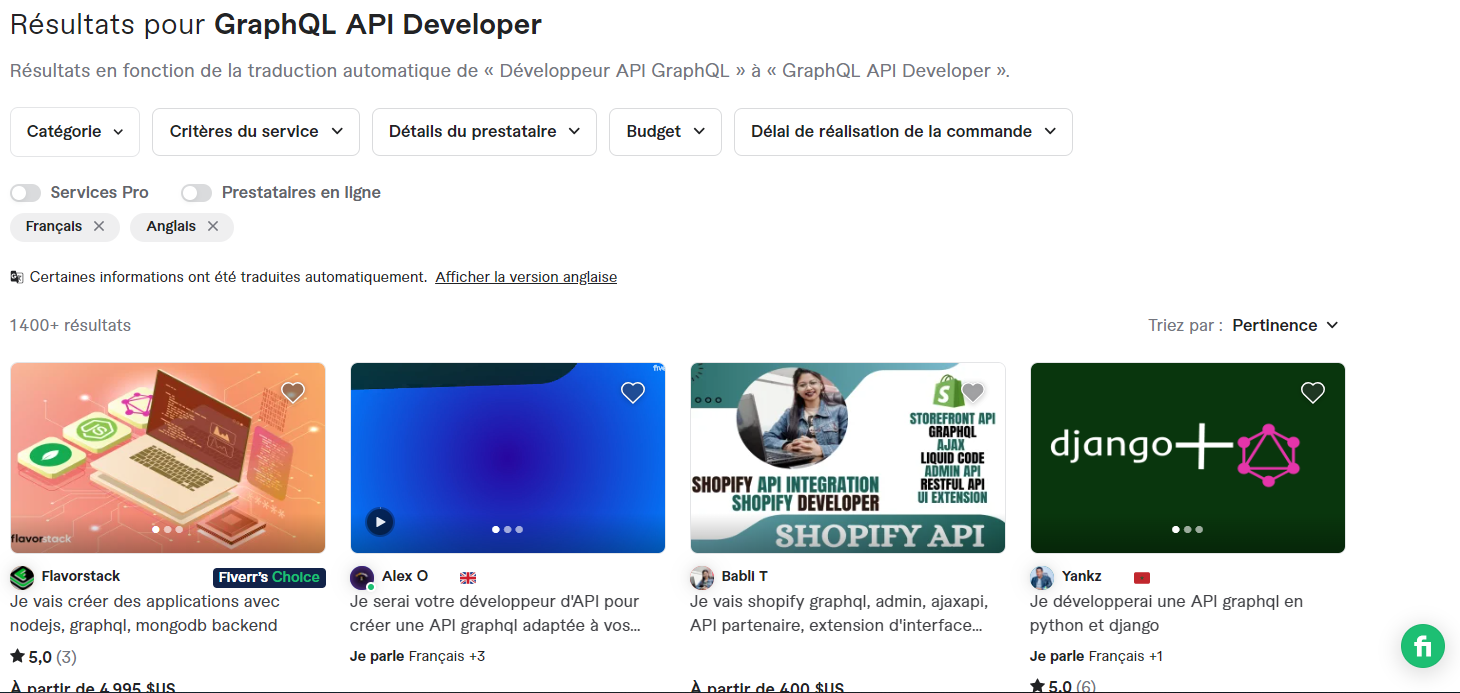
Bilan : 1.444 prestataires ( et à peine 75 qui parlent au moins le français)
À l’inverse, les développeurs d’API REST parlant français et/ou anglais sont 15.180 ! (et 656 quand je ne prend que ceux qui parlent français).
Je vous laisse faire les calculs vous-mêmes pour voir la différence de taille dans le vivier de talents disponible sur la technologie GraphQL.
4 – Sécuriser les serveurs est plus compliqué
Sécuriser un serveur utilisant une API GraphQL présente des défis en termes de cybersécurité plus importants qu’avec une API REST.
La raison ? les réponses des points terminaux (les clients) ne sont pas statiques comme dans une API REST.
Bien sûr, il y a des moyens pour les sécuriser, sinon Facebook et tous les autres géants de la tech ne l’utiliseraient pas 😉
Et hop, transition parfaite pour le prochain point.
Comment sécuriser son API GraphQL ? (4 méthodes)
 Logo de GraphQ
Logo de GraphQOn est d’accord, GraphQL a ses avantages, si ça fait de votre système informatique une passoire pour hacker, hors de question de l’utiliser.
Heureusement, il existe une myriade de techniques pour transformer vos API GraphQL en coffres-forts anti-hackers.
1 – Restreindre les autorisations
Oui, GraphQL permet à l’utilisateur de demander les données qui l’intéressent.
Mais encore faut-il qu’il ait l’autorisation de lire tous les champs de données qu’il demande.
Raison pour laquelle, l’un des moyens les plus sûrs pour diminuer le risque d’attaque informatique est de limiter les autorisations.
Couplé à une politique d’authentification robuste et le chiffrement des données et vous êtes presque invulnérable.
Enfin, une autre technique consiste à surveiller les activités de l’API pour identifier et neutraliser les menaces. Ainsi, même si les identifiants d’un utilisateur sont compromis, vous pourrez rapidement repérer la source de l’attaque et la bloquer.
2 – La validation des requêtes de l’API
L’API peut être une source d’attaque.
Comment ? Il suffit que l’attaquant demande des informations sensibles ou injecte du code malveillant via un appel-serveur.
Évitez ça.
Pour cela, rien de plus simple : pensez à toujours vérifier les inputs/outputs de l’API et à les nettoyer au besoin.
Ça vous évitera notamment des attaques par injection.
3 – Gérez la complexité des requêtes avec soin
Vous vous souvenez de ce que l’on disait que GraphQL permet de limiter l’under-fetching en récupérant directement toutes les données ?
Ça aussi, ça peut être une source de vulnérabilités informatiques.
Si un individu malveillant parvient à faire une requête profonde, il peut récupérer un lot d’informations sensibles. Ou pire, il peut surcharger les serveurs qui hébergent vos données via une attaque par déni de service DDoS.
Pour parer à ça, une seule solution : limitez la profondeur et l’étendue des requêtes.
4 – Soyez vigilant sur les demandes d’introspection
L’introspection est une fonctionnalité de GraphQL qui permet au développeur de connaître le schéma de votre base de données.
Elle révèle absolument tous les champs… ce qui peut vite devenir problématique si un individu malveillant utilise cette fonction.
Raison pour laquelle il est nécessaire de toujours restreindre et gérer soigneusement les données exposées via les points de terminaison.
Comment faire pour implémenter une API GraphQL ou une API REST sur votre projet ?
Ok.
À ce stade, vous savez ce qu’est GraphQL (et REST, vu que j’en ai beaucoup parlé). Et vous voulez savoir si ça peut booster les performances de votre application web/mobile ou de votre logiciel.
Alors comment faire ?
J’aimerais bien vous donner une réponse type faite A puis B puis C, seulement, votre projet est unique. Et les solutions techniques dont vous avez besoin le sont aussi.
Alors, j’ai une autre réponse à vous donner : venez en discuter avec notre chef de projet informatique.
En lui exposant votre projet, il pourra alors mieux vous conseiller et vous dire que faire.C’est par ici pour le rencontrer.